AG百家乐下载 英伟达新GPU再王炸, 也得靠蹭DeepSeek卖卡
发布日期:2024-02-12 09:17 点击次数:85
孤立皮衣黄仁勋AG百家乐下载,GTC2025上自以为是。
固然最近英伟达的股票跌得比较狠,致使来到了10年来的最低点,但这不影响老黄,对最新的GPU们信心满满。
时期回拨到2月初,DeepSeek的发布在AI界限掀翻巨浪。一个中国团队的居品,仅用了一丝的低端GPU(以A100为主)蒸馏现存超大模子就完了了高端GPU(以H100为代表)才有的性能。
高端GPU并非刚需,谁还成吨地采购你老黄的Hopper、Blackwell核弹?昔时在AI行业被奉为金口御言的“ScalingLaw”(范围定律),也即是“模子参数目、数据集、考验本钱越多越好”的不雅念也被严重冲击。
这几年谷歌、Meta、微软等互联网大厂成吨地采购H100芯片以看守范围,恰是想以算力分赢输、定存一火。咫尺压根不需要如斯恐怖的范围,也能让大模子领有忘形OpenAIo1的性能。
一时期,声称DeepSeek能让英伟达走上死路的声息连绵络续,迥殊是国外的社媒平台发酵最快、传播最凶。有X网友更坦言“英伟达的一切齐将开动领会”,这段时期里英伟达的股票一天地落13%、17%齐成了常态。
不外,也有另一种声息称,从恒久来看DeepSeek的告成反而利好英伟达。
DeepSeek揭示了不错通过“蒸馏现存超大模子”的门径考验性能出色的大模子,但仅仅不需要用到H100芯片这等性能怪兽长途,并非扫数不依赖规画卡。A100规画卡,亦然英伟达家的居品。
玩家的门槛镌汰了,入场的玩家当然会越来越多,从市集总量来说,对算力的需求如故会高潮的。英伟达又是全寰球最大的卡街市,总会卖出更多的规画卡。
再说了要蒸馏现存的超大模子,也得先有性能出色的超大模子存在才行,到底如故需要H100这么的规画卡集群来考验超大模子,这似乎是个“先有鸡如故有蛋”的问题。
只可说两种声息齐很是念念兴味,不外公共最想知谈的如故老黄本东谈主的声息。
此次GTC2025,咱们终于比及老黄的躬行修起。
如故阿谁GPU霸主
按照常规,咱们先来总结一下这场光门票就要价1万好意思元的“科技盛宴”。
简便来说,英伟达主要发布了四款芯片架构、两款AI电脑、一款AI考验底层软件和展示了具身机器东谈主有关的发达,其他内容就不赘述了。
4款AI芯片架构,划分是将在2025下半年发布的BlackwellUltra、2026下半年发布的VeraRubin、2027下半年发布的VeraRubinUltra,和2028年的Feynman。
全新的超等芯片居品方面,基于BlackwellUltra架构的GB300NVL72芯片是上代最强芯片GB200的继任者,推理是GB200NVL72的1.5倍,晋升幅度不算大,致使在大会上GB300的径直对比对象如故2年前的H100。

从市集的反应来看大部分东谈主对GB300不太买账,它莫得上一代GB200的那种“横空出世”的惊喜感,要说最大的升级点,可能是HBMe内存晋升至288GB,即是有点“苹果本年发布的新机是2TB版块的iPhone16ProMax”的滋味了。
重头戏是英伟达改日的芯片架构筹划,下代超等芯片RubinNVL144,比GB300NVL72强了3.3倍;下下代的RubinUltraNVL576性能是GB300NVL72的14倍,从画饼给出的性能来看,改日简略率如故会由英伟达掌抓GPU算力王座。

两款全新的AI电脑,划分是搭载了GB10GraceBlackwell超等芯片的DGXSpark,每秒可提供高达1000万亿次AI运算;搭载了GB300GraceBlackwellUltra的DGXStation,不错提供每秒可提供高达2000万亿次AI运算。咫尺DGXSpark一经开动预售,要价3000好意思元。
开源软件NVIDIADyamo,不错简便知道为一款AI工场(数据中心)的操作系统,英伟达说在NVIDIABlackwell上使用Dynamo优化推理,能让DeepSeek-R1的隐约量晋升30倍。
具身机器东谈主的时期储备,包括机器东谈主通用基础模子IsaacGR00TN1、一款配备了GR00TN1模子的机器东谈主:Blue,和GoogleMind、迪士尼配合的最新恶果。

从发布的居品来看,英伟达如故阿谁GPU界限的霸主,致使相通地位一经开动向AI拓展。它们不仅将居品时期门道图更新至一年一更,改日三年的居品号称“超等大饼”,围绕AI有关的软件建筑也在马上鼓吹,NVIDIADyamo很可能会是改日数据中心的标配。
对于DeepSeek的冲击,英伟达似乎也有了科罚的目标。
干预“token时期”
终于,黄仁勋初度在公开形势,正面修起了DeepSeek降生以来对公司变成的冲击。
最初他把DeepSeek重新到脚吹了一遍,说DeepSeekR1模子是“超卓的革命”和“寰球级的开源推理模子”,况兼他淡定地示意,不睬解为什么公共会把DeepSeek当成英伟达的末日。
至于因DeepSeek而起的对于ScalingLaw撞墙的征询,老黄在会上给出了我方的知道。
最初,他在大会上对ScalingLaw进行了一次迭代更新:
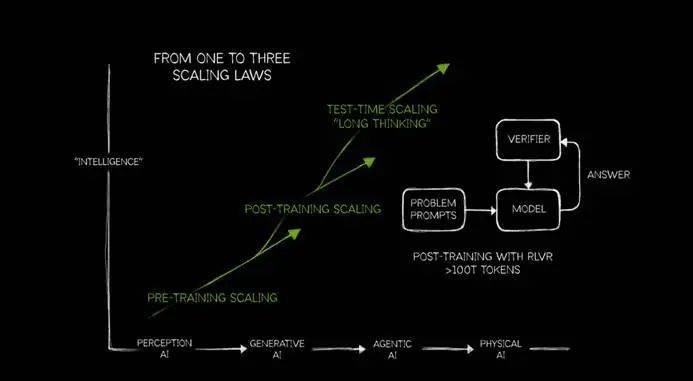
咫尺他将ScalingLaw细化为PRE-TRAININGSCALING、POST-TRAININGSCALING、TEST-TIMESCALING三个部分。老黄的兴味是,跟着AI干预到不同阶段,对Scaling的需求是不休提高的。
这里要提一下,老黄认为AI的发展分为四个阶段:感知东谈主工智能(PerceptionAI)、生成式东谈主工智能(GenerativeAI)、代理东谈主工智能(AgenticAI)和改日的物理AI(PhysicalAI)。而咫尺咱们正处于代理东谈主工智能阶段。
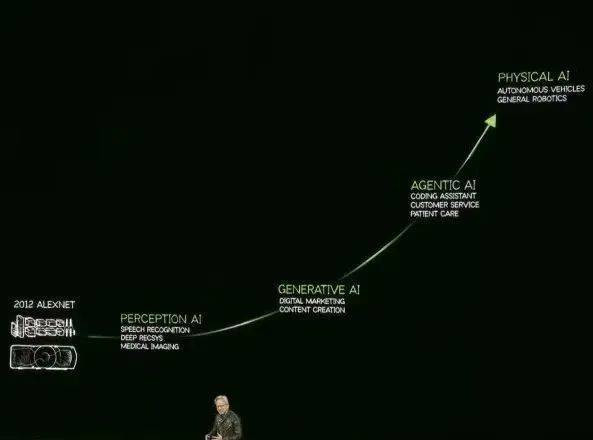
现阶段由于推理模子、AI代理的爆发,骨子上愈加需要Scaling,愈加需要算力。
其背后的环节是token。
以推理模子为例子,模子进行推理时,token的消费猛涨。用老黄的话,咱们不仅需要让token的隐约量晋升十倍,还需要昔时10倍的算力来晋升token的输出速率,最终,需要的算力是之前的100倍。
从时期上来说,这不无兴味兴味。比拟传统的生成式模子,比如ChatGPT,咱们不雅察到它莫得列举推理形势。输入问题→提供谜底,没中间商差价,谜底所呈现的即是最终消费的token数。
而领有念念维链的推理式模子,比如公共熟知的DeepSeekR1,会有一连串的推理历程,有些时候可能推理历程的字数比谜底还要多。
R1模子能够完了推理,是因为会将输出的token复返上司从新念念考、推理,正如譬如大家老黄所说的“每个token齐会自我怀疑”,在不休的怀疑-论证中,形成了推理的历程。但这也会更多地消费算力和token,推理模子要比传统生成式模子多消费的token不是2倍,而是20倍。
是以,ag百家乐可以安全出款的网站咱们用推理模子时,一大串的念念考、推理历程要在前台展示出来,不仅因为用户不错从大模子的推理历程介入修正谜底,还因为它们不是白送的,不是免费的,而是在消费一个个token,齐是真金白银,花了钱的所在确定得让你看到。
况兼市面上的推理模子越来越多,更多的传统模子也络续开动加入推理历程,比如谷歌的Gemini,最终token的消费会呈指数级增长。
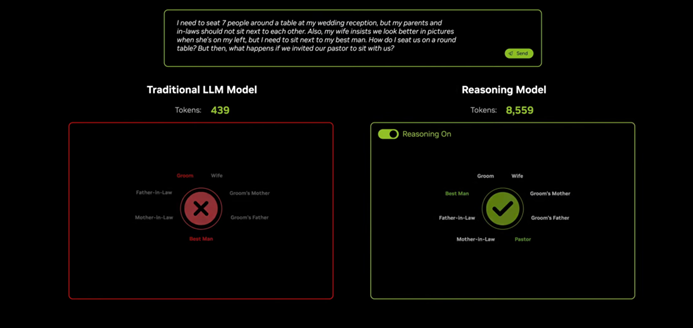
这即是老黄确信ScalingLaw莫得失效的底气。在会上,老黄用传统模子Llama3.370B与DeepSeekR1671B进行了对比,结伴回答一个复杂问题。最终前者消费了400多个token但戒指不可用,后者的戒指号称竣工,但足足消费了8559个token。
未必从蒸馏大模子的点子中量入为主的算力,又会消费到推理的历程中,说不准这即是AI算力中的能量守恒呢。
DeepSeek让英伟达GPU卖得更好
除了黄仁勋的情感论证,一个事实是,在这个高token消费时期,英伟达的GPU确切卖得更猛了。
彭博社报谈,OpenAI预测在“星际之门”首期策动中,建立一个不错容纳40万个英伟达的AI芯片的数据中心概括体。一齐装满的话,这会是寰球最大的AI算力集群之一。
还有对算力珍重终点的马斯克,旗下的xAI已与戴尔达成50亿好意思元契约,用于在孟菲斯建筑超等规画机的AI就业器;Meta也晓谕策动要领有相配于600,000块英伟达H100芯片的算力。
还有国内的阿里、小米、腾讯等公司,也将部署海量算力四肢主要策动。这背后的显卡供应商,毫无疑问齐主要来自英伟达。推理模子铺开后大公司们对规画卡、算力的矜恤涓滴不减,看来至少大公司们仍信赖改日是算力的时期。
在个东谈主腹地部署界限,DeepSeekR1也莫得确切地邋遢个东谈主用户的算力包袱。
2月中,全网掀翻了一阵腹地部署DeepSeekR1蒸馏模子的激越,但从个东谈主的教化来看,想要得回较好的模子性能,对电脑建树,也即是算力的要求一丝齐不低。
以RTX408016GB显卡为例,领有9728个CUDA中枢,16GBGDDR6X的显存带宽为736GB/s,在显卡中一经算高端。
但用它在腹地部署14B的DeepSeekR1蒸馏模子时,大部分的推理速率只须20-30tokens/s,需要分析深度问题通常需要恭候进步10分钟。
如果更进一步用它来部署32B的蒸馏模子,推理速率会进一步下降到5-15tokens/s,生成通常的回答,就需要恭候进步30分钟。
这么的服从明白是不可的。如果想要提高推理速率,有两个目标:
遴荐更小参数的蒸馏模子部署,但推理的精度、谜底的可靠性会彰着下降;
遴荐更高建树的硬件,比如RTX5080/5090,用5090部署32B的蒸馏模子,推理速率也能达到50-60tokens/s,服从彰着晋升,但又让老黄卖卡的策动通了。
也许大大宗东谈主的算力要求,腹地部署的大模子还不如径直掀开腾讯元宝高效。
因此,从DeepSeekR1实验出来的“蒸馏模子量入为主考验算力”一经被“推理模子消费算力”抵消,这给了英伟达全新的机遇,不错说DeepSeek的出现为英伟达关上了一扇门,又掀开了一扇窗。
最终,咱们不得不承认长久来看算力的需求还会不休加多,如故利好英伟达。虽说本年BlackwellUltra挤牙膏,但背面几年的芯片架构齐会有彰着的算力晋升。当各大厂的算力吃紧时,老黄的核弹们,又有大展拳脚的契机了。
贩卖token焦急?
纵不雅GTC2025,只若是触及AI、GPU、算力的部分,老黄齐离不开token,致使有善事的媒体专门统计了他在会上提到“token”的次数,还怪幽默的。
在新ScalingLaw时期,token仿佛成了英伟达的救命稻草。固然从逻辑上看老黄的不雅点说得通,但如斯时常地重叠一种逻辑,就像咱们在著述中连结写100次“token”,若干会有东谈主认为,英伟达有点歇斯底里。
自农历新年以来,英伟达的市值一经跌去了快要30%,此次发布会的黄仁勋不再像一个时期大拿,不像是阿谁“全寰球最智谋的科学家”、“全球最牛公司的CEO”,而像一个絮唠叨叨的金牌销售,通过贩卖token焦急的格式,让公共确信英伟达仍掌抓着改日。
不外投资者的信心不来自倾销和布谈,而来自居品。事实即是本年下半年面世的GB300照实莫得太多亮点,画的大饼又比较远处。反馈到股价上,发布会收尾后英伟达的股价依然下落了3.4%。
其实更令我哭笑不得的是价值3000好意思元的DGXSpark,凭据官网透露的信息这款居品的128GB内存,带宽只须273GB/s。
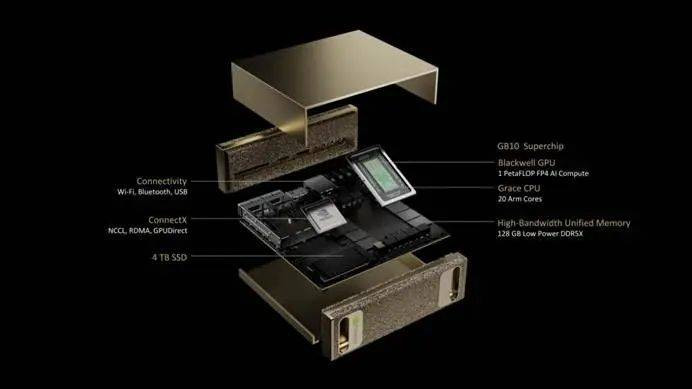
尽管老黄将它界说为“可用于腹地部署”的AI电脑,但这性能真不敢捧场。不说满血版671B的DeepSeekR1,跑大部分32B的模子可能也只可完了2-5tokens/s的输出服从。用它来跑传统的模子应该还不赖,但推理模子忖度是很贫困了。
未必它存在的意旨,停留在“让公共买更强的DGXStation”上落幕。仅仅如果你一直在贩卖token焦急,最佳能拿出更多能科罚token焦急的居品来。
英伟达咫尺枯竭的不是时期和居品,在GPU界限一骑绝尘,第二名齐看不到车尾灯;确切枯竭的,是抵消费者的诚意。
参考尊府:
APPSO《刚刚,黄仁勋甩出三代核弹AI芯片!个东谈主超算每秒运算1000万亿次,DeepSeek成最大赢家》
第一财经《凌晨AG百家乐下载,黄仁勋紧要晓谕!》