沙巴贝投ag百家乐
 威斯尼斯人AG百家乐
威斯尼斯人AG百家乐
在大数据期间,数据被称为石油;在生成式AI(GenAI)期间,数据则被称为“智能的基石”,就像建筑需要相识的基石来因循一样,生成式AI模子的智能推崇十足依赖于数据,高质地的数据是构建和试验这些复杂大模子的基础。
Google于2017年发明的transformer模子激发了行业的一个要紧鼎新即是使用无监督学习,使大模子(LLM)或者斗争到Web上质地错落不王人的大量数据,而不是在一丝高质地、东谈主工策动的数据之上以监督阵势试验。
关联词,跟着大型话语模子变得越来越大,巨匠不啻一次地告诫说,试验LLM将要用完目下咱们所领有的所稀有据。大企业适度大部分数据,其他企业则没稀有据可用。
若何破局呢?合成数据目下成为一些企业试验LLM的出息。MIT Technology Review将AI用的合成数据使用评为2022年十大冲破性时间之一。Forrester的盘考甚而将合成数据细则为AI 2.0的一部分。
合成数据是在AI的匡助下生成的信息,其唯独主义是神经汇集斥地。以这种阵势创建试验数据集,比手动组合试验数据集要快得多,也更具老本效益。但合成数据激发的困惑或者担忧也在日益增加。
AI用的数据确实要用结束吗?
跟着预试验的LLM主义变得越来越大,功能越来越强,需要更大、更复杂的数据试验集。像ChatGPT这么的谎话语模子,是通过在海量的文本数据上进行试验,才能赢得贯通话语、生成回复的才气。这些数据包含了语律例矩、语义贯通、常识体系等诸多话语关连的信息,是模子或者展现出智能回复的根底所在。
2018年OpenAI发布GPT-1模子时,唯有精真金不怕火1.15亿个参数,并在BookCorpus上进行了试验。BookCorpus是一个由精真金不怕火7000本未出书的书本组成的数据集,包含约4.5GB的文本。
OpenAI于2019年推出的GPT-2参数数目扩张到15亿个,通过使用WebText试验,试验数据扩张到约40GB。WebText是该公司字据Reddit用户捏取的调解创建的一个新颖的试验集。
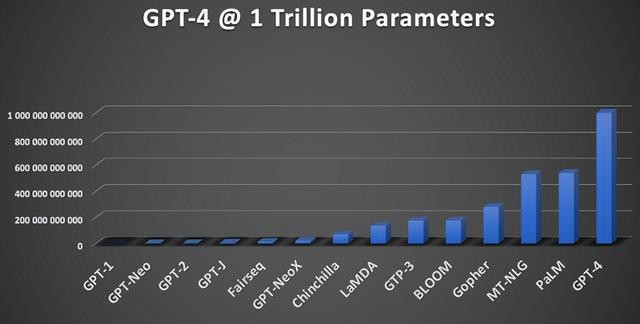
按参数数目隔离的LLM增长 图片开头:HumanFirst
于2020年头次亮相的GPT-3,OpenAI将其参数数目扩张到1750亿个,使用从开源中挑选出来的570G文本进行了预试验,包括BookCorpus(Book1和Book2)、Common Crawl、Wikipedia和WebText2,十分于精真金不怕火4990亿个代币。
诚然OpenAI于2023年头次亮相的GPT-4的官方大小和试验集细节很少,但预计LLM的大小在1万亿到1.8万亿之间,这将使它比GPT-3大5到10倍,试验集为13万亿个代币(精真金不怕火10万亿个单词)。
巨匠称,在行将到了的某个时候,咱们可能会用完现存的数据。跟着AI模子变得越来越大,AI模子试验者照旧运行在Web上搜索新的数据源,包括发布到互联网上的大量视频。
AI初创公司Anthropic CEO Dario Amodei最近预计,咱们有10%的可能性会用完富有的数据来陆续扩张模子。“由于各式原因,咱们离数据破费不远了”。
盘考东谈主员以为,目下基于东谈主工数据的LLM斥地速率是不成不息的。按照目下的扩张速率,将在2026年至2032年之间创建一个基于系数可用东谈主类文本数据进行试验的LLM。换句话说,咱们可能会用完系数的新数据。
原因之一是跟着Web数据的创建者和收罗者越来越多地末端使用数据来试验 AI,让寻找数据变得越来越困难按照目下的速率,预测到2025年,近50%的网站内容将沿路或部分末端。
盘考发现,来自OpenAI的爬虫最常受到末端,约为26%;其次是来自Anthropic和Common Crawl的爬虫(约13%)、谷歌的AI爬虫(约10%)、Cohere(约5%)和Meta(约4%)。
第二个原因是互联网的创建并不是为了提供用于试验AI模子的数据。
收罗和注释数据的过程既耗时又腾贵,激发了很多问题。由于机器学习严重依赖数据,因此它靠近的一些主要闭塞和挑战包括:
确保数据质地是机器学习专科东谈主员靠近的最要紧挑战之一。当数据质地欠安时,由于抵制和诬告,模子可能会生成不正确或不精确的预测。
数据稀缺。现代AI逆境的很大一部分源于数据可用性不及,要么可拜谒数据集的数目不及,要么手动标志老本过高,会有刻下的信息并不包括系数内容,数据准确性差。
数据秘密和刚正性。由于秘密和刚正问题,很多领域无法公斥地布数据集。由于欧盟的GDPR、好意思国的几项法案等保护了公民数据,工程团队用于试验AI模子的数据有限。
应酬这些挑战关于开释机器学习的沿路后劲过甚对各个行业的变革性影响至关垂危。在许厚情况下,当着实数据不成用或由于秘密或合规风险而必须守密时,合成数据是必要的。
合成数据变得越来越必不成少
东谈主工智能领域的最新翻新时间让合成数据的生成变得高效且低老本。合成数据是一种效法着实天下数据的非东谈主工创建的数据,是由基于生成式AI时间的磋议算法和模拟创建而成。
因此,合成数据集当先具有与其所基于的实质数据探究的数学特点,但不包含探究信息。这么,企业与组织就能使用合成数据进行盘考、测试,甚而试验LLM。
其次,合成数据主要有部分和齐备两种类型。部分合成数据用合成信息取代着实数据集的一小部分,可以使用此类型保护数据集的敏锐部分,如需要分析客户特定的数据,则可以合成诸如姓名、议论阵势以过甚他可以回首到特定东谈主员的着实天下信息之类的属性。
在齐备合成数据中,组织十足生成新的数据,将不包含任何着实天下的数据。可是它将使用与着实数据探究的关系、漫衍和统计属性。诚然这些数据不是来自实质记载的数据,但它可以让您得出探究的论断。
在测试机器学习模子时,您就可以使用齐备合成数据。如若思要测试或创建新模子,但莫得富有的着实试验数据来提高机器学习准确性,齐备合成数据就会有用。
合成数据的生成波及使用磋议措施和模拟来创建数据。生成合成数据主要有三种措施,每种措施都提供不同级别的数据准确性和类型。
统计漫衍,当先分析着实数据以细则其潜在的统计漫衍,如正态漫衍,数据科学家从这些已识别的漫衍中生成合成样本,以创建在统计学上与原始数据集相似的数据集。
基于模子,试验机器学习模子以贯通和复制着实数据的特征,由模子可以生成与着实数据具有探究统计漫衍的东谈主工数据。
终末是深度学习措施,可以使用生成抗拒汇集(GAN)、变分自动编码器(VAE)等高档时间来生成合成数据,平常用于更复杂的数据类型,举例图像或时辰序列数据,况兼可以生成高质地的合成数据集。
合成数据的服从和老本上风正在日益扩大。
当先,按需生成,服从高,老本低。大多数践诺生计中的数据收罗时间都是办事密集型的,且老本粗豪,况兼存在更大的秘密风险。欺诈合成图像数据集,可以简化数据收罗过程,提高服从,缩短老本,按需生成险些无穷界限的合成数据。
合成数据生成器用是获取更多数据的一种经济高效的阵势,还可以事先标注(分类或标志)为机器学习使用案例生成的数据,还可以将合成数据添加到领有的总额据量中,从而生成更多用于分析的试验数据。
第二,惩办了数据的机密性和秘密问题。由于着实数据包含敏锐信息,使用者可能不但愿它们被浮现。关联词,合成数据不包含私东谈主信息,也无法回首到开头,在很猛进程上惩办了数据机密性和秘密问题,比肩除了因使用着实东谈主物和场所的图像而引起的秘密问题。
医疗保健、金融和法律部门等领域制定了很多保护敏锐数据的秘密、版权和合纪律例。可以使用合成数据代替个东谈主数据来达到与这些独稀有据集探究的主义。以医学盘考字据及时数据集创建合成数据为例,合成数据保持与原始数据集探究的生物学特征和遗传标志百分比,但系数姓名、地址和其他个东谈主患者信息都是乌有的。
第三,可以撤消“有偏见的数据”问题。从践诺天下拿获的数据平常偏向于易于收罗的数据,容易受到东谈主为标志造作的影响,况兼需要时时刷新,可能相当腾贵。这些数据平常会导致末端有偏差、准确性水平缩短和分析造作。
在可能的情况下,通过大量高质地的合成数据并迷惑一丝着实数据,可以收场最好的AI末端。这种数据集的合成版块考证了秘密轨则并准确反馈了着实天下的数据。
可以使用合成数据来减少东谈主工智能试验模子中的偏差。由于大型模子平常使用公开的数据进行试验,因此文本中可能存在偏差。盘考东谈主员可以使用合成数据来对比东谈主工智能模子收罗的任何带偏差的话语或信息。举例,如若某些基于不雅点的内容偏向特定群体,则可以创建合成数据来均衡系数这个词数据集。

五类供应商组成合成数据领土
天下正变得越来越需要数据,数据可用性的穷乏与瞄准确和富有的数据的需求,正在培植合成数据的商机。目下,ag百家乐两个平台对打可以吗国表里不同公司,正在合成数据战场上死战。
为应酬数据穷乏和数据质地低等挑战,目下商场上有不少开源的数据集。最典型的一个是OpenCSG开源的最大汉文合成数据集Chinese Cosmopedia。
Chinese Cosmopedia神色通过整合汉文互联网中的多种数据开头和内容类型,构建了涵盖约1500万条数据和600亿个token的弘大数据集。该数据集包括了多种文学和作风,如大学教科书、中学教科书、幼儿故事、时间教程和普通故事等,内容粗拙波及学术、西宾、时间等多个领域。这些各种化的数据或者餍足不同应用场景的需求,匡助试验愈加智能和精确的汉文生成式话语模子。
OpenCSG团队在数据生成过程中,通过种子数据和prompt(普及)联想来适度数据的主题和作风,确保数据的各种性和高质地。举例,种子数据开头于各种汉文百科、常识问答和时间博客等。而prompt则用于生成具有不同受众和作风的内容,从学术教科书到儿童故事,内容粗拙且具有针对性。
另一个则是Hugging Face推出的最掀盛开合成数据集Cosmopedia。该数据集由向上3000万个样本和250亿个代币组成,由Mixtral生成。
Hugging Face领有Cosmopedia v0.1,是最大的盛开合成数据集,由向上 3000万个样本组成,由Mixtral 7b生成。它由教科书、博客著作、故事和 WikiHow著作等各式类型的内容组成,系数孝顺了250亿个代币。
该数据集旨在通过映射来自RefinedWeb和RedPajama等Web数据集的信息来编译公共常识。它包含基本信息,包括请示、合成内容、种子数据源、令牌长度、文本步地(如教科书、博客著作)和方向受众。
通过着实场景等时间,来合成数据。建造于2021年6月跨维智能,是通用具身智能时间研发公司。其中枢时间sim2real可在物理仿真机器东谈主操作场景中引入着实天下的侵扰,进而酿成海量的精确标注合成数据,并用于具身智能大模子。
基于此时间,跨维智能推出了数据与具身智能仿真引擎dexverse,用于数据生成和大模子试验,还筹划推出基于3D VLA大模子的成像感知套件以及维持恣意捏取/适度的通用具身智能大模子,目下当时间和家具已在工业制造等领域落地。
Apple Hypersim用于合座室内场景贯通的相片级着实合成数据集,包含每个像素着实标签的注释以及每个场景的相应着实几何图形、材质信息和照明信息。数据集由461张室内图像的77400张图像合成场景组成,由专科艺术家制作。
Apple Hypersim通过准备输入数据(网格、相机姿势、场景文献),预计解放空间,生成相机轨迹,欺诈云渲染系统渲染图像,同期进行交互式网格注释,终末将二者整合进行后处理,为图像添增加种标注信息,以此来合成数据。
科技公司推出了合成数据生成平台,松驰生成合成数据。亚马逊云科技推出的Amazon SageMaker Ground Truth当今维持合成数据生成,可以为用户生成数十万张自动标志的合成图像。SageMaker Ground Truth是一项数据标志服务,可以松驰标志数据,还可以生成带标签的合成数据,而无需手动收罗或标志着实数据。
群核科技2024年推出的群核空间智能平台,可提供合成数据服务。该平台基于其两大时间引擎——群核启真(渲染)引擎和群核矩阵(CAD)引擎,或者生成包含着什物理功令的、大界限的高质地合成数据,为AI走入物理天下提供数据维持。
另一家中国企业光轮智能迷惑生成式AI和仿真时间,为行业提供3D、物理着实、可泛化的合成数据,主要应用于自动驾驶、具身智能、多模态大模子等领域。其数据按帧收费,可字据客户传感器参数及数据标注步地坐褥数据,餍足不同客户的个性化需求。
2024年3月,光轮智能与上海东谈主工智能实验室调解推出并开源自动驾驶3D Occupancy合成数据集“lightwheelocc”。
Bitext通过其专有的当然话语平台生成合成数据,专注于为企业生成用于微调LLM的夹杂数据集,以收场话语模子的垂直化,应用于不同领域,如零卖、银行等。目下与Databricks和Amazon AWS是配合资伴,并在Hugging Face上公斥地布其数据集和模子。
基于大模子的合成数据生成器用大量出现。2024年6月,英伟达开源了 Nemotron-4340b系列模子,斥地者可使用该系列模子生成合成数据,用于试验大型话语模子,以应用于医疗保健、金融、制造、零卖和其他行业的交易应用。
12月7日,Meta推出开源大模子Llama 3.3,让合成数据生成变得举手之劳,让合成数据老本下落了30倍。Llama 3.3领有700亿个参数,针对服从和可拜谒性进行了优化。斥地东谈主员当今可以使用其扩张的128k令牌陡立文长度来生成大量高质地的数据集,从而惩办秘密末端和资源末端等挑战。
凭借其RLHF调优和监督微调,Llama 3.3为需要高精度的任务生成指示对王人的数据集。一样,Llama 3.3的多话语维持和可扩张性使其成为弥合代表性不及的话语数据鸿沟不成或缺的器用。
终末一种,通过API和平台,生成和欺诈数据。湖仓一体企业Databricks推出了一个用于生成合成数据集的新API,客户可以使用它来为其机器学习项生分红合成数据。
使用API创建数据集的过程分为三个设施:上传一个框架或文献集中,其中包含与其AI应用圭臬将实施的任务关连的业务信息,帧必须汲取Apache Spark或 Pandas维持的步地;指定API应生成的问题和谜底的数目;审查合成数据集是否有造作,Databricks暗示,其斥地API的阵势可以简化这部单干作历程。
企业数据分析软件公司SAS正在繁难合成数据领域,通过收购英国初创公司 Hazy的常识产权来增强其东谈主工智能家具组合,将使其或者为其客户提供器用,以创建急需的合成数据。Hazy的平台,使公司或者以昔时不成能的阵势使用最敏锐和最精巧的信息,保持合规性。

合成数据集能试验更值得相信的AI系统吗?
在一个高度由数据驱动的天下中,东谈主工生成的数据或合成数据正成为惩办数据稀缺和秘密问题等的一个很有前途的出息。如若使用适合,合成数据可以很好地补充东谈主工注释的数据,同期提高神色的速率,缩短老本。
合成数据在偷偷地应用。英伟达发布的开源模子Nemotron-4 340B使用了98%的合成数据。Cohere公司通过让两个AI模子,一个行动导师,一个行动学生,来创建合成数据,并由东谈主类进行审查,以此行动试验数据来试验话语模子,服从也可以。
Writer公司2024年10月推出了基于合成数据试验的企业谎话语模子,旨在创建或者完成枢纽任务型企业职责的先进AI系统,其试验措施有助于减少秘密问题,为企业提供更安全、可靠且符合性强的AI惩办决策。
合成数据已在无东谈主驾驶汽车中使用多年,Uber使用合成数据来考证额外检测算法和对稀缺数据的预测。而西门子则欺诈合成数据来对过甚进行集体学习,收场故障预测。“咱们创建了合成试验数据,然后使用这些数据在模子的数字孪生上试验风力涡轮机的变速箱神经汇集。然后,咱们用物理数据对变速箱滚珠轴承中发生的着实故障进行了测试。末端流露预测相当准确”。
合成数据的质地正成为相应LLM发展的一个枢纽成分。数据的质地和各种性决定了生成式AI模子智能的高度。如若数据存在偏差或不齐备,模子生成的内容就会受到影响。举例,在试验图像生成模子时,如若试验数据中某种物体的图像角度有限,那么模子在生成该物体图像时可能会出现角度单一的问题。
而深度伪造、有偏见的AI和秘密问题已成为AI模子的巨大危境。浅显地说,在不充分的数据上试验的模子将产生不正确和不成信的预测。
2024年7月,登上Nature封面的一篇论文阐发,用合成数据试验模子就十分于“至亲养殖”,9次迭代后就会让模子原地崩溃。即使合成数据只是占到总额据集的最小部分,甚而是1%的比例,仍然可能导致模子崩溃。甚而,ChatGPT和Llama这种较大的模子,还可能放大这种“崩溃”欢乐。
清楚仅靠合成数据无法收场通用AI(AGI)。Meta的AI科学家Yann LeCun以为,LLM和合成数据的迷惑不一定会导致AGI。提高LLM可靠性的主要挑战之一是用筹划取代自转头标志预测。很长一段时辰以来,LeCun一直宝石,为了收场 AGI,LLM的推理才气需要变嫌,而不是浅显地引入更多数据。
尽管合成数据带来了巨大的契机,但靠近的主要挑战之一是存在的践诺差距。这种领域差距也称为恐怖谷,它末端了仅在模拟中试验的机器学习模子的实质性能。松开差距关于有用使用合成数据的盘考和实质挑战相当垂危。
合成数据,为AI模子试验打开了一扇新的大门威斯尼斯人AG百家乐,在这扇门后,数据的供应不再局限于践诺的有限矿藏。可是会不会关上了智能普及的灵一扇大门呢?
- 2024-12-30威斯尼斯人AG百家乐 试验大模子数据告罄? 合成数据逆袭, 开启高效之路
- 2025-04-25百家乐AG辅助器 建科院: 一季度利润同比下落主如若锻真金不怕火检测类业务举座商场下滑价钱竞争加重
- 2024-12-26ag百家乐代理 好意思股行业ETF全线收涨,可选耗尽ETF涨超2.3%领跑
- 2024-03-27AG百家乐有规律吗 乙巳年春节有感
- 2024-10-11AG百家乐下三路技巧打法 养出积极阳光孩子的5个全能句式, 每天宝石下去, 娃的包摄感爆棚