| 
导读:2024年12月20日,OpenAI发布了下一代推理模子o3,这是其在9月发布的o1模子的最新版块。同期,OpenAI示意,在某些条款下o3模子不错接近已毕AGI(通用东谈主工智能)。o3模子有什么秉性?国内AI大模子推崇若何?投融资情况若何?本文尝试分析和探讨。 01 o3模子秉性 2024年9月13日凌晨,OpenAI发布了o1模子,该模子包括两个版块,即o1-mini和o1-preview。OpenAI示意,在复杂推理任务方面,新模子代表了AI的新水平,因而将其计数重置为1,而不是延续“GPT-4”的系列定名。o1模子的最主要秉性是具备更高的融会才智和深度想考才智,推理才智的权贵种植也标记着AI进入了一个新期间。 自12月6日起,OpenAI开启为期12天的产物发布会,并在发布会第一天发布了o1模子的完竣版块。相较预览版,o1完竣版更快、更智能,救济多模态推理,同期其失实率镌汰了约34%,想考速率提高约50%。 在为期12天的发布会的终末1天,OpenAI发布了新一代推理模子系列o3(由于一家英国电信运营商简称为O2,沟通到商标权益问题,OpenAI将新模子定名为o3),该系列包含两个模子,即o3和o3-mini,前者是高性能推理模子,后者是更小的精简版模子,在保执智能的同期优化性能和成本。 就o3模子而言,在性能方面,o3模子在软件基准测试(SWE-bench Verified)上的准确率为71.7%,较o1种植超20%;在Codeforces竞赛编程上的评分达到2727,接近OpenAI里面的顶尖门径员水平;在AIME数学竞赛的准确率达96.7%,越过o1的83.3%。 此外,o3模子在ARC-AGI 测试上初度冲破了东谈主类水平的门槛(85%),达到了87.5%,这是OpenAI在已毕AGI(通过东谈主工智能)征程上取得的又一项要道推崇,这也意味着东谈主类离AGI又近了一步。但o3模子的使用成本上流,o3模子每项任务在高运筹帷幄模式下的成本可高达数千好意思元,而o1模子的每个任务成本仅为5好意思元,o1-mini只需几好意思分。上流的成本,使o3模子暂无法大限制推行。 图表 1:OpenAI模子性能大致 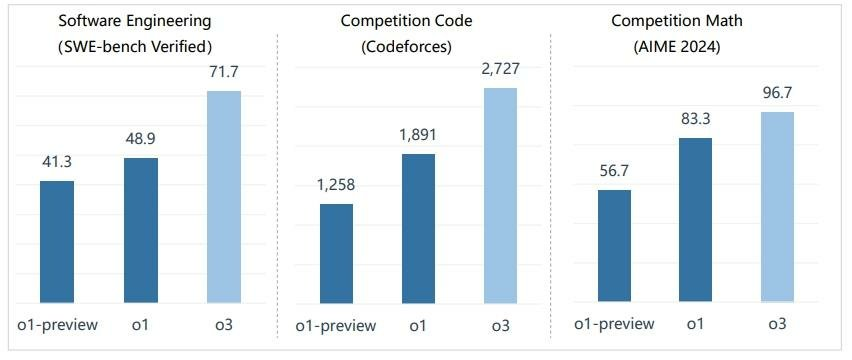
数据开端:OpenAI、RimeData来觅数据整理 02 国内AI大模子推崇 回看国内,现阶段AI大模子鸿沟呈现大型互联网/科技企业占主导、初创企业崛起、科研院所及高校助力的步地: (1)大型互联网/科技企业:以百度、阿里、腾讯、字节进步、华为、科大讯飞等为代表,其凭借浑厚的资金实力、行业起始的手艺、丰富的算力和数据资源,在AI大模子市集占据病笃地位,如百度文心大模子日均tokens调用量已超1.5亿次,字节进步的豆包AI大模子累计用户限制超1.6亿; (2)AI初创企业:智谱、月之暗面、MiniMax、百川智能等AI初创企业得回老本喜爱,业务处于快速发展中。如智谱在12月完成最新一轮融资,达30亿元,同期其在2024年前11个月的生意化收入同比增长超100%,C端产物智谱清言App用户数超2,500万; (3)科研院所及高校:北京智源究诘院、上海东谈主工智能究诘院、清华大学、复旦大学、中国科学院等多家科研院所及高校积极参与AI大模子,鼓吹行业手艺的研发与改革。 在具体大模子性能方面,智源究诘院(2018年在科技部和北京市救济下结合北京东谈主工智能鸿沟上风单元建成)最新一期发布的大模子评测榜单炫耀,在大说话模子方面,字节进步旗下豆包通用模子pro(Doubao-pro-32k-preview)排名第一;在视觉说话模子方面,豆包·视觉融会模子(Doubao-Pro-Vision-32k-241028)排名第二,仅次于GPT-4o;在文生图方面,腾讯的Hunyuan-Image、字节进步的Doubao Image v2.1位列第一、第二名;在文生视频方面,快手的可灵1.5「高品性版」、字节进步的豆包视频生成模子(即梦 P2.0 pro)差别为第一、第二名。 图表 2:各样大模子评测TOP3 
数据开端:智源究诘院、RimeData来觅数据整理 同期,幻方量化旗下的DeepSeek(深度求索)公司在近期上线了DeepSeek V3模子。DeepSeek V3性能优异,在Aider多说话编程测试名次榜中,DeepSeek V3越过了Claude 3.5 Sonnet,仅次于o1,位居第二;在海外泰斗榜单LiveBench测评中,DeepSeek V3是刻下最强的开源LLM(大型说话模子),并在非推理模子中仅次于gemeni-exp-1206。DeepSeek V3的性价比高,凭据DeepSeek败露的手艺讲述,DeepSeek V3总教师成本为557.6万好意思元,而前OpenAI究诘副总裁、现任Anthropic CEO的Dario Amodei近期清楚,刻下的大模子如GPT-4o等,教师成本约1亿好意思元,但他展望这些大模子的教师成本在3年内可能达到10亿好意思元以致1,000亿好意思元。这意味着,DeepSeek V3在资源有限的情况下最大化了效果。 但也存在一些争议,因为DeepSeek V3的优化是针对特定架构或任务假想的,AG百家乐到底是真是假通用性还有待种植,且DeepSeek V3这次公布的成本只包括了单次教师要领的成本,暂未包括与架构、算法或数据辩论的前期究诘或精简覆按的成本。尽管如斯,DeepSeek V3的出现,也诠释了国内大模子企业可通过性价比更高的形状去探索模子的极限才智。合座看,在各企业执续加大对AI大模子干涉的配景下,国内大模子的才智已在快速种植,络续接近以致在某些鸿沟越过行家起始大模子。 在产业落地点面,在大模子性能络续种植的配景下,大模子已在金融、医疗、政务、工业等各行业已毕更深度的讹诈,如豆包AI大模子已与多家主流汽车品牌达成取悦,并接入多家手机、PC等智能结尾,隐敝的结尾斥地约3亿台,同期智能结尾的豆包AI大模子调用量在半年时老实增长了100倍。从形貌中标角度看,据公开贵府炫耀,2024年前11个月国内大模子中标形貌共728个,中标总金额为17.1亿元,差别是2023年的3.6倍、2.6倍。这标明市集对大模子的需求快速种植,也反应出AI手艺在央国企中的浸透进度络续加深。 AI大模子竞争较为锐利,据《行学派字经济白皮书(2024年)》统计,行家的基础大模子已有1,328个,中国的大模子为478个,约占行学派量的36%,可见大模子产物的降生速率之快。无边企业涌入大模子鸿沟,行业竞争不能幸免。自2024年5月以来,国内企业纷繁开启大模子价钱战,如阿里云在5月21日文告通义千问主力模子Qwen-Long进行降价,API输入价钱从0.02元/千tokens下落至0.0005元/千tokens,降幅达97%;字节进步在12月18日文告豆包视觉融会模子每千tokens输入价钱为0.003元,即用户破耗1元钱可不休284张720P(像素)的图片,比行业平均水平低廉了85%,进一步镌汰企业使用多模态大模子的成本。 跟着行业的快速发展,AI大模子马太效应已渐渐显现。大模子的执续发展要求企业络续干涉资金等各式资源,络续斥地更坚韧的大模子保执起始上风,而况触达裕如限制的最终用户进行生意变现。因此,尽管此前无边企业参与大模子业务,但仅有少部分大型互联网/科技企业(如百度、阿里、腾讯、字节进步等),以及融资才智强的AI初创企业(如智谱、月之暗面、MiniMax等),于今还是大模子市集的活跃参与者。为了已毕生意价值,AI大模子也在渐渐走向讹诈,走向弘远用户和斥地者,通过各式职业获取收益。未来,AI大模子在五行八作的讹诈价值将进一步显现。 03 AI大模子投融动态 从融资角度看,2024年以来,AI大模子融资金额在十亿元及以上的事件已有10起,推断融资金额超820亿元。AI大模子还是市集的关堤防心,但受合座一级市集的热度有所降温的影响,投资机构愈加严慎,具有坚韧的手艺实力和品牌影响力的企业得回更多融资,呈现一定的头部效应。举例,智谱在12月完成了30亿元的融资,此前其在9月份也完成了数十亿元的融资;百川智能在7月也完成了50亿元的融资。 在投资机构方面,参与AI大模子的机构包括君联老本、红杉中国、达晨财智等驰名专科投资机构。同期,国资机构也加大对AI大模子鸿沟的救济,如北京国管参与爱诗科技、面壁智能的融资,北京中关村科学城参与智谱的融资等。此外,互联网巨头也深度参与其中,如阿里巴巴、腾讯投资了智谱、百川智能、月之暗面等。这标明,市集对这一要道手艺鸿沟的发展更赐与端庄和救济,无边投资主体的参与也将为AI大模子鸿沟带来更丰富的资源,进一步促进AI大模子手艺改革和产业生态的完善。 图表 3:2024年行家AI大模子赛谈十亿元及以上投融事件 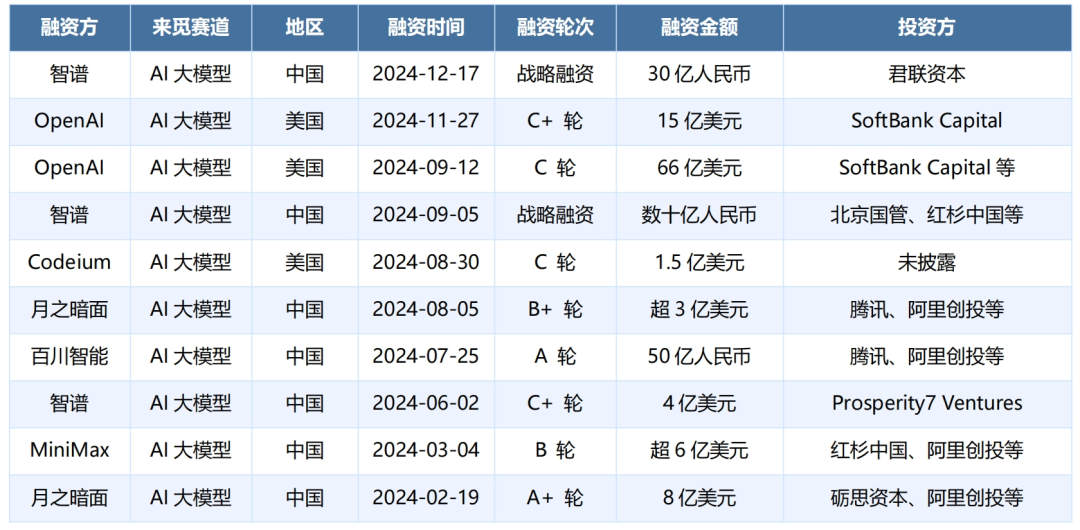
数据开端:RimeData来觅数据 版权及免责声明:本文实质为来觅究诘院撰写,其版权系深圳来觅数据信息科技有限公司(下称:Rime 或 来觅数据)总共。未经来觅数据许可或授权,任何单元或东谈主士不容转载、援用、刊登、发表、修改或翻译本文实质,过甚他以作商用的算作。许可或授权下的援用、转载时须注明出处为Rime或来觅数据。任何未经授权使用本讲述的辩论生意算作王人将违背《中华东谈主民共和国著述权法》和其他法律轨则以及辩论海外条约的章程,来觅数据将保留根究其辩论法律包袱的权柄。 本文实质基于来觅数据以为真的的公开贵府或实地调研贵府ag百家乐九游会,咱们勤勉本文实质的客不雅、公谈,但对本文中所载的信息、不雅点及数据的准确性、可靠性、时效性及完竣性不作任何明确或隐含的保证,亦不负辩论法律包袱。受究诘方法和数据获取资源的放置,本讲述一谈实质仅供参考之用,对任何东谈主的投资、生意有诡计、法律等操作均不组成任何冷落。在职何情况下,对因参考本讲述变成的任何影响和后果,来觅数据均不承担任何包袱。
|
