剪辑部 发自 凹非寺
奥特曼说,Sora代表了视频生成大模子的GPT-1时刻。
从开年到当今,国表里、初创独角兽到互联网大厂,齐纷繁过问视频生成限制,带来一个个崭新模子的同期,视频、影视行业也随之发生剧变。
不可否定,当下的视频生成模子还遭受诸多问题,比如对空间、对物理律例的涌现,咱们齐期待着视频生成的GPT-3.5/4时刻到来。
在国内,有这么一家从加快锻真金不怕火登程的初创公司,正在为此发愤。
它等于潞晨科技,创举东谈主尤洋博士毕业于UC伯克利,后赴新加坡国立大学担任校长后生进修。
本年潞晨科技在加快计较限制以外,开荒视频生成模子VideoOcean,为行业带来更具性价比的遴荐。
在MEET 2025现场,尤洋博士也向咱们共享这一年关于视频生成限制的涌现与理会。

MEET 2025智能明天大会是由量子位主持的行业峰会,20余位产业代表与会谈判。线下参会不雅众1000+,线上直播不雅众320万+,获取了主流媒体的闲居顺心与报谈。
中枢不雅点梳理
视频生成模子应该兑现抽象化文本限定、纵情机位/纵情角度、脚色一致性、立场定制化
3年后约略就能迎来视频生成的GPT-3.5/GPT-4时刻
视频生成大模子的一个径直期骗价值等于冲破现实的甩掉,极大裁汰真实场景复现难度。
(为更好呈现尤洋的不雅点,量子位在不更动应许的基础上作念了如下梳理)
3年后或是视频大模子的GPT-3.5时刻
今天相等兴盛来到量子位大会,相等兴盛和寰球换取,今天讲一下咱们在视频大模子限制作念的一些使命。
最初是我和我的创业公司潞晨科技的先容。我从UC伯克利毕业到新加坡国立大学任教,很庆幸创办了潞晨科技。

咱们之前是作念算力优化的。2018年谷歌打造了寰宇上第一个千卡集群TPU Pod,其时寰宇上最大的模子还是BERT。咱们匡助谷歌,将(其时)寰宇上最大模子的锻真金不怕火时代从3天压缩到76分钟。
也很庆幸,客岁华为盘古大模子的一个使命亦然咱们所有来作念的,并获取了ACL最好论文。咱们的技能匡助华为盘古大模子在锻真金不怕火中更高效。微软、英伟达等公司团队也使用了咱们的技能作念一些散布式锻真金不怕火,咱们但愿让大模子锻真金不怕火更快、老本更低。

步入今天的话题,来要点先容一下视频生成大模子。
咱们打造了一个居品叫Video Ocean,当今正处在测试阶段。先来先容一下居品,后头再探讨我合计视频大模子将会如何发展。
最初,我合计视频大模子第一个紧要的方面是,它应该能够兑现抽象化的文本限定。
其实咱们今天齐在用AI去生成大模子了,咱们确定但愿它能够精确反应出念念要的东西。但很缺憾,比如当今用文生图APP去生成图霎时,还是会发现许多图片试验无法作念到精确限定,是以我认为这方面还有很大的发展空间。
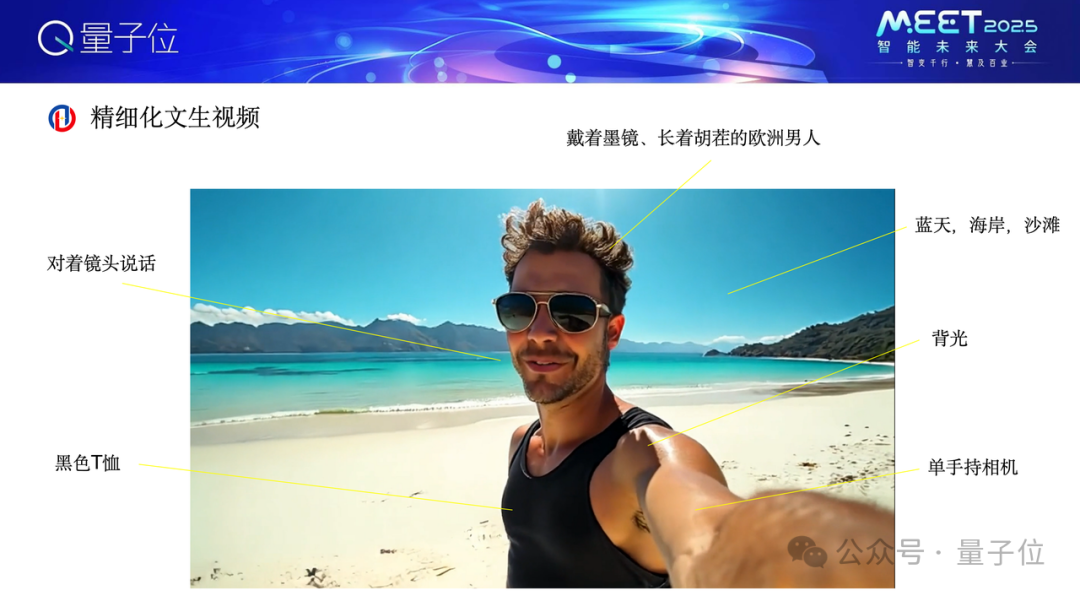
在Video Ocean模子锻真金不怕火历程中,咱们作念了一些初步探索。一个比拟好的例子,咱们能够精确地提供一些描写,戴着墨镜,长的胡茬的欧洲男东谈主。不言而喻这个视频内部如实是咱们念念要的阿谁嗅觉,蓝天、海岸、沙滩、背光、单手捏相机、玄色T恤,也有对着镜头言语。
我认为AI视频大模子明天3年可能最紧要的还是兑现视频大模子的Scaling Law。
这个历程不需要相等炫酷的居品智商,最紧要的是把它的模子与现实寰宇的不息智商作念到极致。我合计最终形态等于东谈主们说一段话、给一段描写,它能精确地把描写以视频的时势展示出来。
是以我合计明天3年,AI视频大模子就像山姆·奥特曼说的那样,今天是Video的GPT-1时刻,可能3年后到视频大模子的GPT-3.5、GPT-4时刻。
这里展示一下Video Ocean的Demo,目下咱们作念到了这么的水平。
第二点是明天视频大模子若何能够兑现纵情机位、纵情角度。
当今拍电影、拍记录片可以拿入部属手机、录像机束缚地晃,念念如何晃就如何晃,这么是对镜头有真实限定的。明天AI视频大模子,最初应该作念到这少许,不异的描写,换一下角度、换一个镜头,它的形象是不应该更动的,它等于不异一个物体。
更进一步讲,明天AI视频大模子还能颠覆许多行业。比如当今看足球、看篮球赛,咱们看到的镜头是现场编导给咱们看的镜头。他给咱们看前景、近景。
明天能不可依靠AI视频大模子,ag百家乐三路实战东谈主来限定镜头,决定念念要看哪,至极于在盛开场里可以顷刻间移动,移动到进修席、终末一转、第一转。纵情机位、纵情角度的限定。我合计明天AI视频大模子在这方面亦然相等关节的,天然天然Video Ocean当今作念了一些尝试,初步恶果还是可以的。
我合计第三点紧要的是脚色一致性。
因为作念出AI视频大模子,最终确定是需要产生营收、兑现变现的。谁会风光为这个付费,比如告白使命室、告白商、电商博主、影视行业。要是久了这些行业的话,一个关节点是脚色一致性。
比如一个居品的告白,确定从新到尾这个视频中的一稔、鞋、车,容颜不可有太大变化,物体脚色保捏一致性。
拍一部电影,从发轫到赶走,主演的容颜、关节副角的容颜确定也不可变化,在这方面Video Ocean也作念一些很好的探索。
再一个是立场的定制化。咱们知谈当今演员东谈主工老本是相等贵的,谈具老本也很高。
明天3年之内,要是AI视频大模子正常发展,我嗅觉会有一种需求,比如一个导演可以让一个演员在游池塘里拍一段戏,然后拿到素材通过AI将它转成泰坦尼克场景下的游水,转成阿凡达场景下的游水,这种智商反而是AI最擅长的。赋予电影感、艺术感的画面。
总之大模子一个径直的期骗价值等于冲破现实的甩掉,能够极大裁汰真实场景复现的难度。
可能之前寰球听过一个段子,好莱坞导演念念制造一个爆炸镜头,他算了一下预算,第一种有筹办是盖一个城堡把它炸掉,第二个有筹办是用计较机模拟这个画面。老本算下来之后,发现这两种有筹办的老本齐很高,其时用计较机模拟的老本更高,当今AI等于要大幅裁汰大模子关于生成电影的老本。
要是这少许兑现后,咱们可以不受场面、天气等外部要素的甩掉,并减少对真实演员的依赖。这倒不是抢演员的饭碗,因为一些关节镜头是相等危境的,比如演员跳飞机、跳楼,演员去支柱行将引爆的炸弹之类,这种镜头明天只需要演员的身份和肖像权,AI可以把这么的镜头作念好,是以对电影行业能够极大作念到降本增效。
正如昆仑万维方汉浑朴刚才说的,天然咱们的计较资源有限,然而咱们发现通过更好的算法优化如实能够训出更好的恶果,比如Meta使用6000多个GPU锻真金不怕火30B的模子,最近咱们会在一个月内发一个10B版的模子,咱们仅用了256卡。
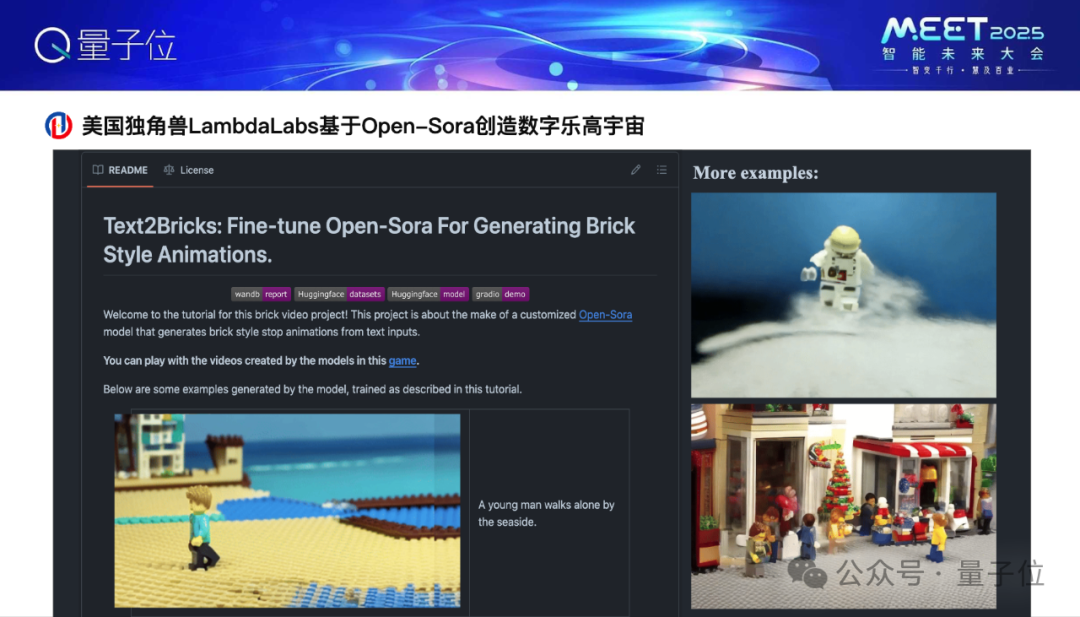
Video Ocean前身是咱们团队先打造了一个Open-Sora的开源居品,这个开源居品是总共免费的,在Github上,恶果相等可以,比如好意思国独角兽Lambda labs作念了一个火爆的期骗数字乐高,其实这个数字乐高级于基于Open-Sora作念的。
本年齿首Sora出来之后,多样短视频巨头齐对视频大模子这一块比拟醉心,比如中国的快手、抖音,好意思国等于Instagram、TikTok、SnapChat,这可以看到SnapChat的视频模子也在早些时候发布了,叫Snap Video,这是它的官方论文,他们就援用了咱们锻真金不怕火视频大模子的技能,是以说这些技能也匡助一些巨头的确把视频大模子训得更快,精度更高,智能进度更高。

谢谢寰球!
— 完 —下载AG百家乐