百家乐AG辅助器 最新大模子被质疑历练“刷分”, Meta承认有破绽但否定舞弊
发布日期:2024-08-22 00:46 点击次数:130

科技巨头Meta酬报了对公司最新开源AI(东说念主工智能)模子Llama4的质疑,否定该模子在历练集配合弊“刷分”。
当地时刻4月7日,Meta的生成式AI认真东说念主AhmadAl-Dahle在外交平台上发布了一篇长文,酬报了关于Llama4的质疑。Ahmad示意,由于Llama4刚开发完就速即发布,是以模子“在不同作事中发扬出了繁芜不皆的质料”,公司会尽快开导破绽。同期,Ahmad否定了Llama4在历练集配合弊“刷分”的说法。
两天前,4月5日,Meta推出了旗下最受接待的模子系列Llama的最新一代模子,包括较小模子Scout和轨范模子Maverick这两个版块。此外,Meta还展示了被称为“迄今最遒劲、最智能”的模子Llama4Behemoth的预览。
据先容,Llama4模子是Llama系列模子中首批聘任夹杂各人(MoE)架构的模子,在多模态性能上发扬出众。其中,起初进的Llama4Behemoth的总参数高达2万亿,担当了其他模子的“安分”;Scout和Maverick的活跃参数目为170亿,Scout主要面向文档选录与大型代码库推理任务,Maverick则专注于多模态智力。

行动原生多模态模子,Llama4聘任了早期和会(EarlyFusion)的本领,通过使用多量无标签文本、图片和视频数据一齐来预历练模子,将文本和视觉token无缝整合到长入的模子框架中。此外,Llama4在长文本智力上也得到了龙套,Scout模子援救高达1000万token的高下文窗口,Maverick模子则援救100万token的高下文窗口。
不外,Llama4还是发布就遭到了质疑。Meta的发布界面显现,在评估代码智力的LiveCodeBench测试集和大模子竞技场(ChatbotArena)中,Scout和Maverick都发扬得很可以。但好多开发者发现,这些模子在袖珍基准测试中的发扬令东说念主失望。
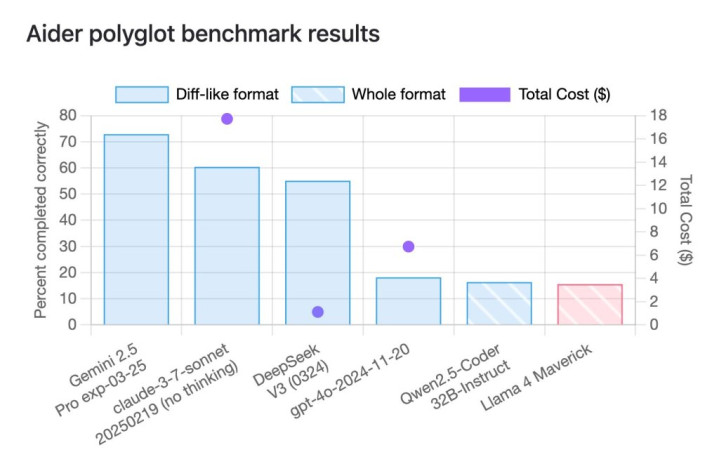
举例,有网友指出,在一项让模子完成225项编程任务的名为aiderpolyglot的基准测试中,Llama4Maverick只得到了16%的得益,AG百家乐是真的么远低于Gemini2.5Pro、Claude3.7Sonnet和DeepSeek-V3等界限附进的旧模子。
AI工程师和本领作者AndriyBurkov则在外交平台X上指出,Meta称Llama4Scout领有1000万token的高下文窗口,而这其实是一个“伪命题”:“本体上,不会有任何模子针对寥落256000个token的指示词进行历练。要是你向它发送这样多token,在大多数时候只会得到低质料的输出。”
关于Llama4令东说念主失望的发扬,一些开发者动手怀疑,为了在测试麇集得到更好的得益,Meta为这些测试集制作了“特供版”Llama4。举例,前Meta征询员、现任AI2(艾伦东说念主工智能征询所)的高档征询员NathanLambert在经过相比测试后指出,在大模子竞技场中得到得益的Llama4Maverick与该公司公开发布的版块不同,前者是“在对话性上进行了优化”的版块。
此外,就在Llama4发布的前几天,在Meta使命了8年的AI征询诈骗JoellePineau文书下野。关系到Llama4的发扬,愈加深了网友关于Llama4“暗箱操作”的质疑。而在国内外交平台上,也有自称为Meta里面职工的网友称“Llama4的历练存在严重问题”,我方已经向公司提交了下野肯求,AI征询诈骗的离任亦然出于同种原因。
这位网友示意:“经过反复历练,其实里面模子的发扬依然未能达到开源SOTA(指在征询任务中发扬最佳的模子),以致与之出入甚远。公司并吞层淡薄将各个benchmark(基准)的测试集夹杂在post-training(后历练)经由中,观念是但愿简略在各风光标上交差,拿出一个‘看起来可以’的遵守。”
可以确定的是,Llama4的启动发布并莫得给AI社区带来重大的积极反响。当今,面临寥落速即的中国AI模子,Meta急于稳住Llama系列在开源界限的起初地位。本年2月,阿里通义千问(Qwen)系列模子的下载量已经达到了1.8亿,累计滋生模子总额达到9万个,滋生模子数超越Meta的Llama系列,成为了宇宙第一掀开源模子系列。
7日本日,Meta(Nasdaq:META)股价涨2.28%,收于每股516.25好意思元百家乐AG辅助器,总市值1.31万亿好意思元。