AG百家乐为什么总是输
热点资讯
你的位置:AG百家乐为什么总是输 > 百家乐AG辅助器 > ag真人百家乐真假 实测会千里想的国产Agent : 深度参谋又能我方干活的AI , 免费不限量
ag真人百家乐真假 实测会千里想的国产Agent : 深度参谋又能我方干活的AI , 免费不限量
发布日期:2024-07-06 03:30 点击次数:50
要是有一个会想考然则不会作念事的AI还有会作念事然则不会想考的AI。
你会选哪个?
要是让我来选,我会说:whynotboth?
今天在中关村论坛智谱OpenDay上,智谱发布了AutoGLM千里想——首个带有千里想才调的桌面端agent。
这是第一个存在于电脑桌面的,能先想考在作念事,且作念的经由中不妄想考的agent。
抛给它一个问题,它会迟缓剖判问题,然后在你面前(或者你不看着它也行)怒放一个又一个浏览器标签页,我方上去搜索、查找、记载、汇总、分析信息,最终为你生成一份经过充分查证和深度想考的限度论说。
要是你还不知谈这是个什么东西,肤浅前情概要一下:
AutoGLM是智谱推出的Agent居品,能够结尾敌手机屏幕和电脑浏览器的操作。要点在于结尾神态是前台的图形界面(GUI),而不是后台的讹诈接口(API)。你可以相识为AutoGLM学习东谈主类通过“手眼并用”的神态,径直在用户界面上进行操作。这和市面上绝大无数基于API的agent居品有着显着的交互神态区别。
而千里想才调,正如字面真理,让AI可以一边想、一边搜,自主解决开放式的、训练语料不包含的问题,效法深度想考和展现深度参谋的才调。智谱在本年3月初拿到新一轮融资的时候就对外预报正在研发千里想,而这个功能的开关也依然在该公司开发的“智谱清言”(ChatGLM)大模子居品里上线了。
而在AutoGLM千里想的身上,智谱特有的GUIagent功能,和东谈主们最追捧和爱用的千里想才调,终于结尾了和会。
AutoGLM千里想背后的模子基座,也在本次OpenDay上崇敬发布:
GLM-4-Air-0414基座模子,具有320亿参数目,但性能足以对标DeepSeek-V3、R1(670B)、Qwen2.5-Max等更大参数目的模子。
但因为参数目更少,GLM-4-Air0414可以快速实行agent类职责,为agent的才调提高以及大范畴落地讹诈提供基础,也一定进度上确保了结尾用户的试用体验。
智谱还发布了GLM-Z1-Air推理模子,比拟DeepSeek-R1(激活37B)推理速率提高了8倍,而老本缩短到只好后者的三十分之一。
这亦然一个可以在破钞级显卡上运行的推理模子,能够显耀提高开发者的使用体验。
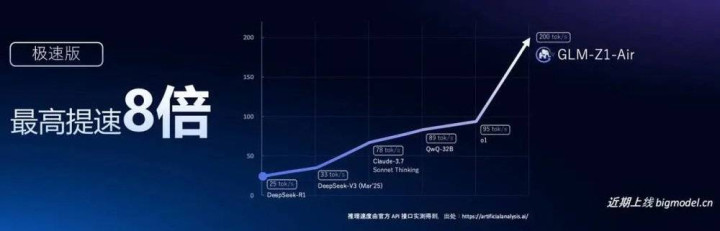
智谱还基于GLM-Z1模子,使用自进化强化学习神态,训练了一个新的千里想模子GLM-Z1-Rumination,能够及时联网搜索、动态调用器用,深度分析和自我考据。这个千里想模子能够自主相识用户需求,在复杂任务中不休优化推理、反复考据与修正假定,使参谋效用更具可靠性与实用性。
也即是说:AutoGLM千里想的基础模子架构是这么的:
中层推理和千里想模子GLM-Z1-Air、GLM-Z1-Rumination+底层说话模子GLM-4-Air-0414
加上工程/居品层的AutoGLM器用,就酿成了AutoGLM千里想的通盘期间栈。
智谱也谋略在4月14日全面崇敬开源AutoGLM千里想背后的整个模子。

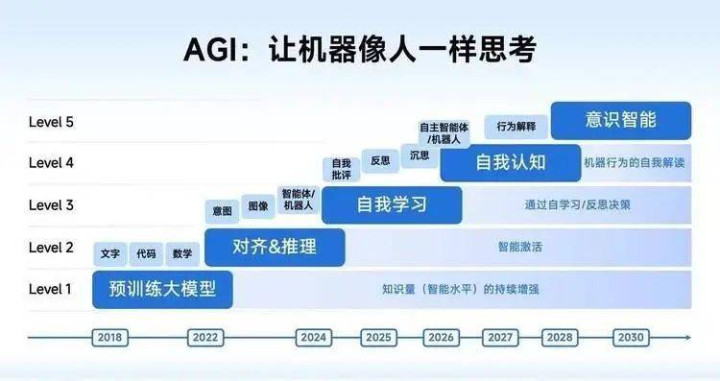
此前智谱曾共享过团队对于AGI门道图的判断:要是用自动驾驶层级打比喻的话,面前大模子居品大体上取得了自我学习的才调,接近于L3;而千里想、反想、自我品评等才调则是L4阶段。
需要提防的是,面前AutoGLM千里想还处于beta测试阶段。上个周末,APPSO深度使用了这个居品。从测试限度来看,它在处理复杂职责上的效果确有提高的空间,底层逻辑也需要优化,但手脚一个异常新颖的大模子-agent居品,总体效果依然令东谈主惊艳。
智谱依然踏入了大模子agent的L4阶段,天然仅仅进来了半只脚。
AutoGLM的千里想功能,面前依然崇敬上线智谱清言网页端、PC端和手机App,免费、不限量地开放。
当Agent有了千里想才调,AI终于学会我方干活了?
客岁Anthropic发布了“ComputerUse”,同期展现了弥散的模子才调以及较强的开采交互才调,让agent(智能体)的设计终于初度得到实践。本年1月,Anthropic在好意思国的最大敌手OpenAI也通过新址品Operator,作念出对于GUIagent理念的演绎。
亦然在客岁10月,智谱和Anthropic简直同期发布了各磨蹭agent方进取的最新尝试。智谱的AutoGLM是第一家国内机构推出的基于GUI的agent居品。
而今天的AutoGLM千里想,不仅将agent的实行任务才调带到了桌面端,更是把器用操作才调、深度参谋才调、推理才协调大预言才调进行了初度和会。
这种多重才调驱动的agent,异常安妥信息检索、索要、汇总型任务。
这就好比是让agent“开车”,曩昔你得给他一辆车,教他标的盘、油门刹车、档位何如用,以致告诉它开车和倒车的时候离别要往哪看——而面前,agent依然可以“自动驾驶”了。
让它制作一份“不同于网上整个主流门道的日本两周小众经典行攻略,要求十足不去最火的主见识,要小众景点,但也要评价比较好的。”
AutoGLM千里想比较准确地拆解了需求,想考逻辑也比较澄莹:它最初去搜了最肤浅的关节词“日本旅游”,了解主流门道和景点,然后又去搜索了“日本小众旅游景点”之类的关节词——通过这几个步伐,它在本次对话的牵挂里面构建了一个常识库,也即什么是主流的,什么是小众的。

这个任务统共作念了20屡次想考。有时候几次想考之间会有相通,比如搜索的是换取的关节词,捕快了换取或者相似的衔尾等。这有可能是因为单次搜索到的信息不及够,毕竟千里想/深度搜索的骨子其实亦然不休地自我怀疑和推翻,直到达到弥散置信度时候才参加下一步。
APPSO还提防到它有点过度依赖特定的网站手脚信息开头,怒放的整个tab里有90%齐是小红书和知乎(各一半傍边)。反而真实的旅行专科贵寓库,比如马蜂窝、穷游,或者哪怕是OTA平台,它一次没用过。
要是要作念一份真实的小众攻略,重度依赖小红书的限度可能并不睬想。毕竟能上小红书的热点札记,这个景点应该并不真的小众。一个真实的小众景点旅行者,只怕不想去momo们依然去过或者齐想去的场所……
APPSO提防到,AutoGLM千里想在千里想事后我方提倡了“门道蓄意合理,不要有无道理的反折”、“行程节律合理,别太特种兵”之类的要求。
仅仅实验限度莫得反馈它我方提倡的这些要求:比如头几天在濑户内海来往折返,有时候一天内去两三个相隔一小时以上的地点,略微特种兵;第二周从青森向南到仙台,然后又从仙台飞机向北大跨度飞到了北海谈,何况北海谈只留了两天。
研讨到日本大跨度旅行基本齐靠JR,票价腾贵,合理的门道应该是顺着一个标的不回头,除非不得不去大城市换车,一般不应该折返。
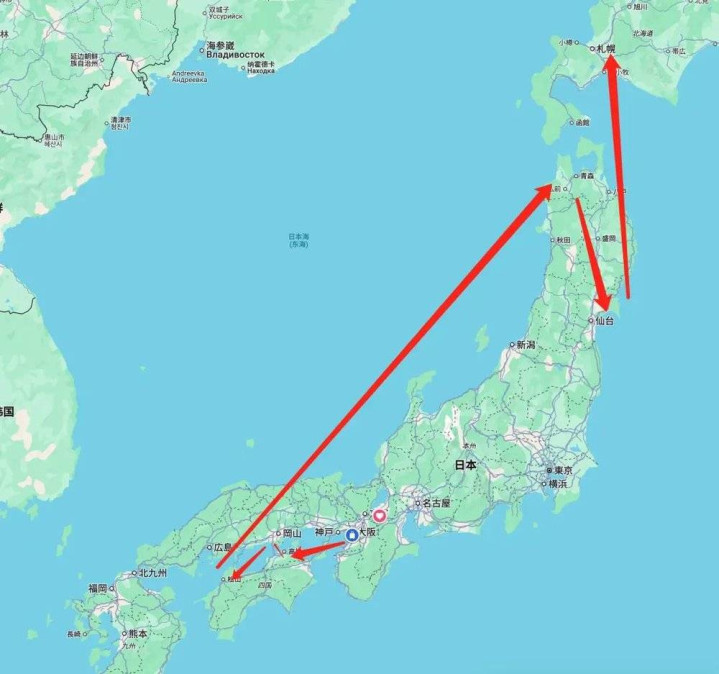
但总体来讲,这份攻略是有用的:它呈现了一些发问者未尝研讨过的主见识,也试图在一次行程里去到季节、模式、格调完全不通常的场所(而不是围在大东京、富士山、京坂奈区域来往打转)。
从这个角度,它盲从了领导的要求,何况展现出了深度想考的限度。
就像你不应该径直把AI生成的限度径直拿去用通常,这份攻略提供了一个还算可以的基础,让旅行者可以自行优化具体的主见识、门道和中间的交通神态。旅行不仅仅上车寝息下车拍照,还应该兼顾东谈主文和天然,久了当地文化传统,探索天然景不雅,以及至少感受一把在当地最有脾性的体验神色。
只消你的期待不是即问即用,AutoGLM千里想给出的谜底是弥散令东谈主自得的。
研讨到AutoGLM千里想与其它深度想考型大模子最大的至极之处在于浏览器的操控才调,AG百家乐为什么总是输APPSO也更久了和严苛地测试了一下他的browseruse才调。
让它作念一份对于科创板云臆想公司的研报,望望限度何如样。
正如前一次作念旅行攻略通常,AutoGLM千里想的“想考经由”是莫得任何问题的。从下图中可以看到,它:
1.准确拆解了筛选要求;
2.明确需要多轮搜索和迭代;
3.制定了分步伐的谋略;
4.通过“一般搜索”找到了大要的搜索谋略;
5.运转实行分步操作。

然则browseruse的经由真实让东谈主有点捏头:AutoGLM器用一次又一次地试图怒放证监会指定的信息知道网站(巨潮资讯),默契网页的信息。它顺利地找到了网站数据库的要求筛选器用,但老是无法正常筛选,要么选不好时候区间,要么找不到对应板块的下拉菜单在哪。
APPSO不雅察到,AutoGLM千里想给每一步伐的定时闲居是3分20秒傍边,但要是捕快网站不顺利,就会因为操作超时而导致“本轮想考”失败。
另外,字据APPSO之前体验客岁的AutoGLM以偏激它GUIagent居品时,当需要用户进行登录操作、输入付款信息、点击发送按钮这种明锐性操作的教训,agent可以停驻来恭候用户操作。而在使用AutoGLM千里想的经由中,它的确可以等候用户登录,但遭逢“用不解白网站”的情况,并莫得呼叫用户给与,而是只会傻傻地等着。
在本次任务中,一语气两轮想考失败之后,AutoGLM千里想运转参加一个再行想考-跟之前导致失败的想考限度通常-再再行想考的轮回经由,一直周而复始了五六次,临了败下阵来,把谋略转向了知乎。步伐进行到这里的时候,其实依然算任务失败了,因为输入的原始指示是查找和汇总上市公司贵寓和公告,数据的专科准确性很伏击,而知乎并不是一个可靠的上市公司信息知道平台。
经过了好几次重荷的测试,临了终于吐出了限度:华为、紫光、UCloud三家公司,天然齐跟角落臆想关联,但三家的股票代码齐写错了,更别提有两家并没上科创板。
Agent“自动驾驶”才调,和路况、驾驶位有很大关系
在其它更“神圣”的任务(比如作念旅行蓄意、游戏攻略、查找肤浅信息等)当中,AutoGLM器用的browseruse才调是莫得太大问题的。
但APPSO发现,一朝刻下网站的视觉设计相对复杂,或者设计的有一些罗网,AutoGLM器用就很容易被“使绊子”。
一个最径直的例子即是电商网站。APPSO给出明确领导,“去淘宝或京东购买一件重磅日系T恤”,AutoGLM千里想制定了宏伟的谋略和明确的单干——关联词却连淘宝首页的山门齐进不去,以致找不到搜索框在那儿。
而且它似乎被“找不到搜索框”这件事完全抵牾住了,以致也莫得去看网页的其它位置——要是它看了的话,细目会发现权衡商品早就出面前首页推选里了。
对于这个测试中发现的无意情况,智谱CEO张鹏默示,“点背不行赖社会”,AutoGLM千里想面前仍在beta阶段,还有很大的进化空间,而且面前的升级速率也很快(APPSO在崇敬发布版上测试淘宝的使用效果依然没那么趔趄了)。
张鹏指出,在模子手脚服务或手脚居品(MaaS)的理念下,模子居品我方的才调要像木桶通常,高且全面。未必面前AutoGLM器用的视觉才调还不如东谈主,处理无意情况的才调还不够,归根结底可能是泛化才调还不够,但这些才调的提高并不是模子问题,而是隧谈的工程层面——不需要惦记。
从模子底座层面,AutoGLM千里想也有提高的空间。
不时用大说话模子居品的一又友齐知谈,领导写的越具体,律例和范围设定的越明确,它的效果越好,越有但愿生成合乎用户领导的限度。基于大说话模子的agent亦然通常。
然则领导不行无尽推广,就好比你招了一个文书帮你干活,但你不应该老是每次齐把“找谁”、“什么地点”、“什么时候”、“去哪”等一切的信息齐讲澄莹,ta才能拼凑顺利地帮你经管一个饭局的准备职责。
大说话模子很庞大,但也有它晦气的场所:只受到文本律例的敛迹,缺少真实的实验问题的蓄意才调,任务经由中容易被卡住;缺少弥散长的高下文牵挂空间,任务赓续时候太长就赓续不下去;上一个步伐的特地会跟着步伐渐渐放大,直至失败。
AutoGLM千里想亦然一个基于大说话模子的agent,即便在agent才调上作念了好多职责,但仍然未免受到大说话模子的诟谇。想考才调越强,越容易想多、想歪。
从APPSO的试用经由中可以看到,除了一些十足基础的主意(比如“旅游”、“T恤”、“公司”)除外,它并莫得略略复杂的表层常识。用户每次发出任何指示,它齐要先我方怒放浏览器,上网学习一遍,明确用户的所指,在本次对话的有限牵挂空间内树立一个常识库,然后再去进行后续的步伐。
而就它面前最擅长和依赖的那几个信息开头来看,一朝用户任务的复杂性、专科性“上了强度”,想要它在用户可接受的时候(面前官方定的是每任务统共15分钟傍边)内,查到真实、准确和有价值的信息,就真的有点拼凑了,更别提给到用户有用的限度(APPSO的测试中有一半无法输出完好意思的限度)。
不外这并不是个太大的问题。
有这么一个很实验的不雅点,可以套用到AutoGLM千里想上:
今天的agent水平,将它视为“主驾驶”可能才调尚有不及。但它仍然是一个很好的副驾驶(copilot)。
在AutoGLM千里想上,咱们看到了弥散的想考才调,也看到了优秀(但如实受制于客不雅成分)的browseruse才调。很显著,智谱手脚中国面前非巨头公司当中,少数模子才调最强的选手之一,细目会在这两个才调上头连续杰出,而且会很快。
自从APPSO拿到测试履历,到AutoGLM千里想崇敬发布,中间依然更新了数个版块,在模子基座和浏览器操控才调上头齐有了改造。
但要是咱们想要的是一个真实会想考且能职业的agent,咱们只怕需要比现存范式的大说话模子更庞大的智能体基座。
而智谱推出的“说话+推理+千里想+行动”的Agent框架,尽管居品层面仍然拙劣,但看起来是一个异常明确可行的标的。
诚然,国产大模子和基于大模子的agent居品,现阶段的谋略要是放在“追逐硅谷敌手”上可能反而更实验少许。AutoGLM千里想从操作逻辑和结尾主见上,齐是显着区别于面前国内整个同类和雷同居品的“新物种”,和Anthropic、OpenAI也正在拉近距离。
对于这么一家非巨头、脱胎于中国顶级学府的大模子调动指点者来说,大无数的不及齐可以被容忍ag真人百家乐真假,而看到它在作念的事情的始创性和指点性,才更伏击。